
|
The Initiative for Cuneiform Encoding (ICE) is an international group of cuneiformists, Unicode experts, software engineers, linguists, and font architects organized for the purpose of developing a standard computer encoding for Sumero/Akkadian cuneiform, the world’s oldest attested writing system.
The first ICE conference was held at The Johns Hopkins University, Baltimore, Maryland, USA, on November 2nd and 3rd, 2000. Conference participants discussed the theoretical and practical issues surrounding the encoding of cuneiform and issued a consensus report. A working group was established to develop a formal cuneiform encoding proposal for submission to The Unicode Consortium. |
First ICE Conference: |
 |
| SEE ALSO:
View the current version of the ICE cuneiform sign database. (In order to view the database you must use at least version 5.0 of Microsoft Internet Explorer for Macintosh or version 5.5 for Windows. Both are downloadable for free from Microsoft. (This requirement is due to the fact that we are posting the cuneiform sign database using XML with XSL style sheets, and, right now, only Internet Explorer supports this, the future of the web.) The current roster of all individuals who have communicated an interest in the Intiative for Cuneiform Encoding. Karljuergen Feuerherm & Lloyd Anderson's Computer Representation of Cuneiform web site Charles E. Jones' Ancient Near Eastern portal site, Abzu For information about ICE contact Dean Snyder at this email address: dean.snyderATjhu.edu (make sure to replace the "AT" with @). For details on how to subscribe to the cuneiform email discussion list see Feuerherm & Anderson's web site. Johns Hopkins University Gazette newspaper article on the first ICE conference. Baltimore Sun newspaper article on the first ICE conference. |
|
|
A LITTLE BACKGROUND
Sumero/Akkadian cuneiform, attested by hundreds of thousands of documents in many genres and several languages from various cultures spanning three millennia, is a complex syllabographic and logographic script system with perhaps a couple thousand distinct graphemes (characters). It is marked by extensive multi-valency - one grapheme can have multiple phonemic and semantic realizations. To this day cuneiform lacks a standard computer encoding. The general practice among cuneiformists of working almost exclusively in Roman alphabetic transliteration, although suitable for its intended purposes, presents difficulties for the application of computers to cuneiform research and instruction. The simple addition of graphemically encoded cuneiform to the current practice of transliteration will enable a dramatic increase in philological and linguistic productivity. (It is important to emphasize that we are not proposing the replacement of transliteration by transcription encoding; rather we are talking about the addition of transcription encoding to transliteration.) For example, with cuneiform encoded: • One could easily search for cuneiform plain text in a mixed script environment, something that is practically impossible in transliteration. One could, for example, search an electronic Chicago Assyrian Dictionary, or the web, for cuneiform content. • One could do context-free text processing of cuneiform - such as automated character recognition of cuneiform tablets (cuneiform OCR) and proximity analysis of grapheme patterns. • Font architects would have much greater incentive to create the many large and complex font sets needed for rendering cuneiform usefully. |
|
|
READING CUNEIFORM
There are two main stages in reading a cuneiform text, the descriptive and the interpretive. In the descriptive phase, one establishes what cuneiform signs, or graphemes, are actually written, i.e.the text is transcribed. This stage requires minimal or no knowledge of what the text means, i.e., it is context-free. |
|
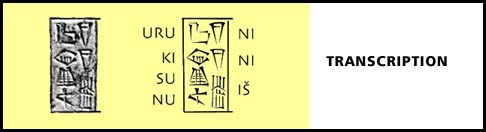 |
|
| In the interpretive phase, one attempts to make sense of the transcription. This is a complex, context-bound, and iterative process which includes sign ordering, transliteration, phonemic normalization (or pronunciation), and translation. | |
 |
|
|
Transcription is what needs a standard encoding.
|
|